I published my first paper Design, Optimization, and Benchmarking of Dense Linear Algebra Algorithms on AMD GPUs, in IEEE HPEC 2020. This was a major project of mine at ICL that aimed to take the existing MAGMA linear algebra library which ran on NVIDIA GPUs, and port it to AMD GPUs. Specifically, it needed to work on the Frontier supercomputer at ORNL, which only has AMD GPUs.
Interestingly, my co-name won the Turing award. He is a legend in the HPC community, and I was very honored to work with him. I’d also like to thank Stan Tomov for mentoring me and helping me get this research job.
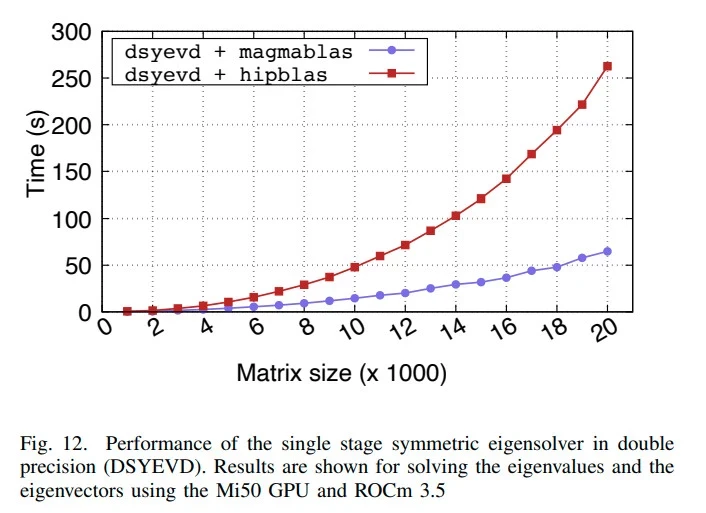
TL;DR: we were able to get 73% faster time-to-solution for solvers, and up to 60x faster for BLAS operations.
We tuned various algorithms (matrix multiplication, rank-k updates) that are common building blocks of machine learning, physical simulations, and other applications. There were a number of obstacles to extracting good performance out of the new hardware; specifically the change in warp size (32 -> 64), new compiler (NVIDIA’s nvcc -> AMD’s ROCm/hipcc), and overall higher peak performance of newer hardware. So much of the HPC ecosystem was built around CUDA, and luckily AMD’s HIP was very similar conceptually.
You can access it at these places
Also, I have a local archive copy here: